usage_log — one line per call — and aggregates it in real
time.
The four token buckets
Anthropic’susage field is normalized into four numbers:
| Bucket | Source | Meaning |
|---|---|---|
raw_input | usage.input_tokens | prompt tokens that missed the cache and did not write it |
cache_read | usage.cache_read_input_tokens | prompt tokens that hit the cache — the key to savings |
cache_write | usage.cache_creation_input_tokens | prompt tokens newly written to the cache this call |
output | usage.output_tokens | tokens generated by the model |
Price table (USD per 1M tokens, 2026 public prices)
| Model prefix | input | cache_read | cache_write 5m | cache_write 1h | output |
|---|---|---|---|---|---|
claude-opus-4-7 / 4-6 | 5.00 | 0.50 | 6.25 | 10.00 | 25.00 |
claude-opus-4-5 / 4 | 15.00 | 1.50 | 18.75 | 30.00 | 75.00 |
claude-sonnet-4-6 / 4-5 / 4 | 3.00 | 0.30 | 3.75 | 6.00 | 15.00 |
claude-haiku-4-5 / 4 | 1.00 | 0.10 | 1.25 | 2.00 | 5.00 |
gpt-5 / gpt-5.1 | 5.00 | 1.25 | 0 | 0 | 15.00 |
deepseek-chat / v3 | 0.27 | 0.07 | 0 | 0 | 1.10 |
_default (unrecognized) | 3.00 | 0.30 | 3.75 | 6.00 | 15.00 |
How savings are computed
Actual cost of a call:cache_control removed, every prompt token at base input
price):
For Anthropic, the
cache_write term is a negative contribution — a write costs 25–100% more
than base price. Only when cache_read volume is large enough (the cache is reused many times) does
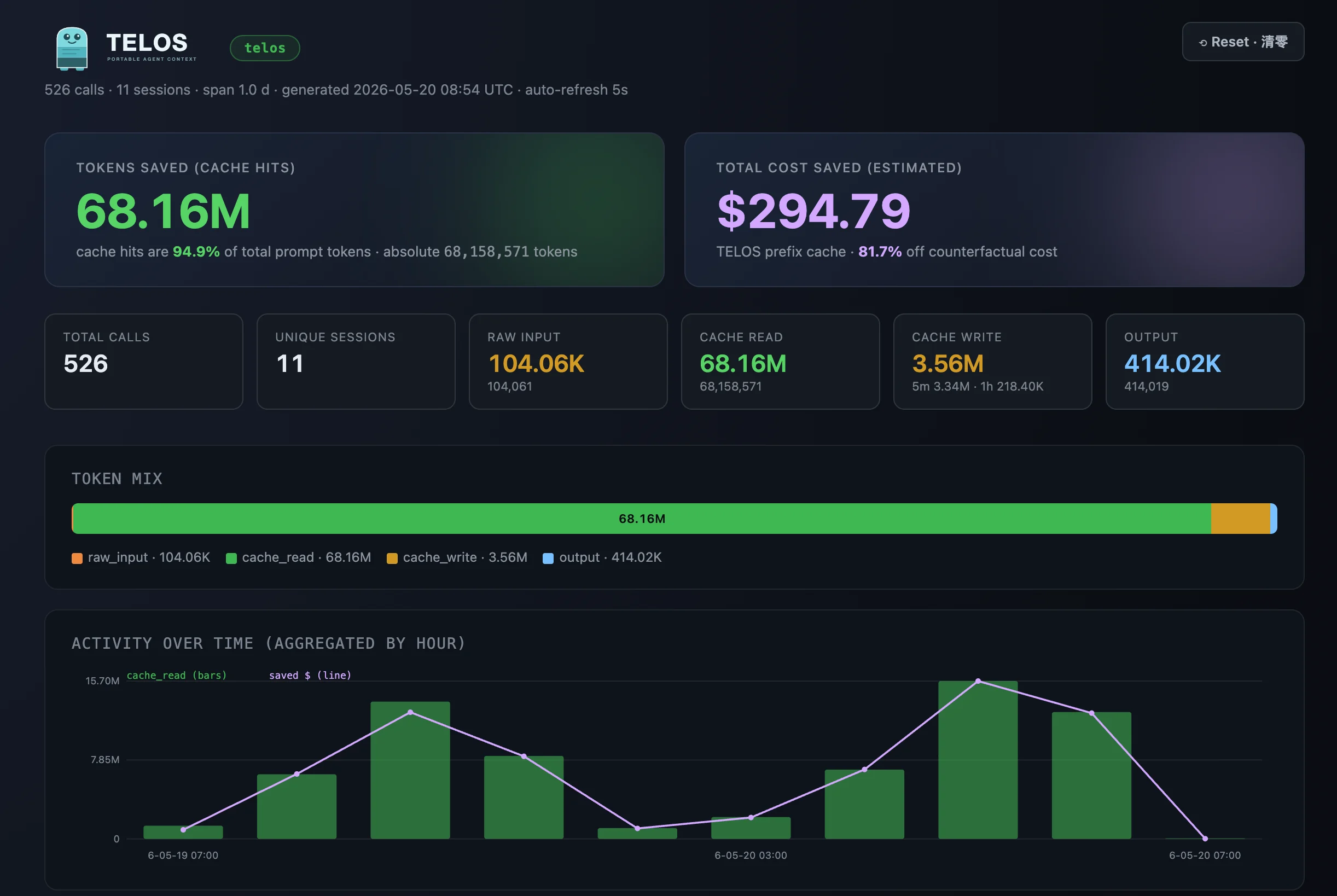
the total go positive. The dashboard’s saved $ already counts this premium against you.What the dashboard shows
- Hero — tokens saved (
total.cache_read) and cost saved (total.saved_usd), with subtitles for hit-% of total prompt tokens and % off counterfactual cost. - KPI bar — total calls, unique sessions, cumulative raw_input / cache_read / cache_write (5m·1h split) / output.
- Token mix — a stacked bar over the four buckets (🟠 raw_input · 🟢 cache_read · 🟡 cache_write · 🔵 output).
- Activity over time — hourly buckets; green bars = cache_read volume, purple line = saved_usd.
- Breakdowns — by harness / model / session, sorted by cache_read descending.
mode, compare_group, and
replay metadata from replay/showcase workflows are kept off this page (use
Replay & Comparison and /__telos/developer.json).
Common questions
Does more cache_read mean more savings?
Does more cache_read mean more savings?
Yes. A token that hits the cache pays only 10% of the price; every extra 1M tokens of cache_read
saves $4.50 on Opus 4.7.
Is more cache_write always better?
Is more cache_write always better?
Not necessarily. Every 1M tokens written to the 5m cache costs $6.25 (25% over input’s $5), and to
the 1h cache $10 (100% over). Only when that cache is subsequently hit many times can the write
premium be amortized. The
saved $ figure already counts the premium as a negative contribution.Why is cache_write in the hit% denominator?
Why is cache_write in the hit% denominator?
Because Anthropic’s
input_tokens refers only to the part that missed and didn’t write the cache,
the true total prompt volume = raw_input + cache_read + cache_write. A smaller denominator
overestimates the hit rate.How is an unrecognized model handled?
How is an unrecognized model handled?
It falls to
_default (estimated at the Sonnet tier). In that case saved $ is an approximate
estimate, not a precise bill.Developer Page
The live in-memory view: IR structure, band distribution, BP slots, and tool stats.